")
한글 인코딩의 이해(유니코드) 완전 기초!
23 Jun 2018 | unicode 유니코드 인코딩 한글주소록 앱 만들기 중 연락처 데이터의 이름에 초성 분석이 필요해서 swift의 UnicodeScalar를 사용했어야 했는데, 유니코드와 한글 인코딩을 처음 접해봐서 기초부터 헤맸다. 한글 인코딩과 유니코드에 대해 기본적인 내용만 이해한대로 정리한 글! 아래의 글을 참고해서 작성했다.
표준 문자 인코딩
- ex) ASCII. 영어 문자 집합의 시초
- 컴퓨터 간에 문자 데이터를 교환하기위해 문자집합을 코드로 표현(인코딩)
한글의 문자 집합
문자 집합: 문자를 표현하기 위해서는 가장 먼저 ‘문자 집합’을 정의해야 한다. 문자 집합은 표현해야 할 문자를 정하고 순서를 지정한 것.
- 영어: ‘A’ ~ ‘z’ (대문자에서 소문자까지)
- 한글: ‘가’ ~ ‘힣’
- CCS: coded character set. 이러한 문자 집합을 행렬로 표기한 형태
- CES: character encoding scheme. 문자 집합을 컴퓨터에 저장하기 위해서 8비트 단위 형태로 표현한 인코딩 방식
- 한글 표현 방법
- 조합형: 한글의 원리에 기반하여 초성, 중성, 종성에 각각 코드를 할당하는 방식
- 완성형: ‘가’,’각’,’간’과같이 완성된 문자에 코드를 할당하는 방식. 한글 표준안이다.
유니코드
- 각 나라 언어에는 컴퓨터에서 해당 언어를 표현할 수 있는 독자적인 문자 집합이 있음
- 하지만 문제는 ‘어떻게 동시에 한국어, 중국어, 일본어를 표현하느냐’
- 하나의 문자 집합을 사용하는 문서에서는 다개국어를 동시에 표현할 수 없었음
- 유럽어의 문자도 마찬가지로 같은 문자지만 문자집합에 따라 코드가 달랐음
- 전 세계적으로 사용되는 모든 문자 집합을 하나로 모아 탄생시킨 것이 유니코드.
- 현재 버전은 2010년 10월 11일 제정된 6.0이다.
유니코드 인코딩 방식
문자 인코딩은 문자들의 집합을 부호화(정보의 형태나 형식을 변환하는 처리)하는 방법이다.
- 유니코드의 인코딩 방식으로는 코드 포인트를 코드화한 UCS-2와 UCS-4, 변환 인코딩 형식(UTF, UCS Transformation Format)인 UTF-7, UTF-8, UTF-16, UTF-32 인코딩 등이 있음
- 이 중 ASCII와 호환이 가능하면서 유니코드를 표현할 수 있는 UTF-8 인코딩이 가장 많이 사용됨
코드포인트
유니코드의 값을 나타내기위해서는 코드포인트를 사용하며, 보통 U+를 붙여 표시함
- ex) A’의 유니코드 값은 U+0041로 표현한다(\u0041로 표기하기도 함)
- 이 중 한글은 U+1100~U+11FF 사이에 한글 자모 영역, U+AC00~U+D7AF 사이의 한글 소리 마디 영역에 포함된다.
유니코드 범위 목록에서 한글 관련 범위

한글표현의 대표적 두 개의 코드영역
- 한글 소리 마디와 한글자모, 한글 자모 확장 이렇게 두 개의 코드 영역이 있다는 것은 같은 글자를 표현하는 서로 다른 두 개의 방법이 있다는 것을 말한다.
- 같은 ‘가’의 글자여도, 표현법에 따라 코드 값이 다르다는 의미.
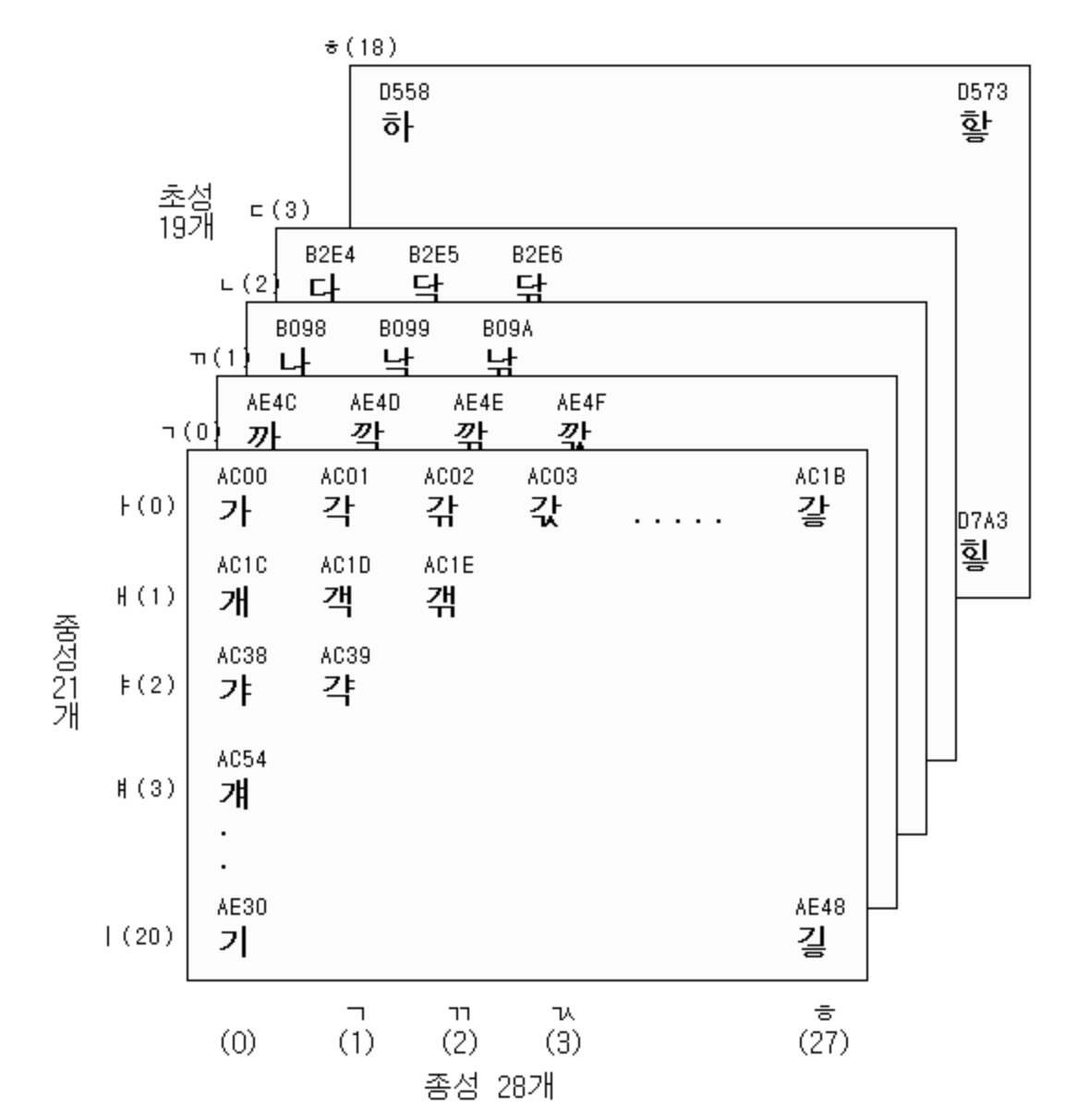
한글 소리마디
- 초성, 중성, 종성으로 이루어진 한글을 표현하기 위한 영역
- 현대 한글에서 표현 가능한 11,172자를 모두 포함 (‘가’ ~ ‘힣’)
- ‘가’(U+AC00) ~ ‘힣’(U+D7A3)
- 완성된 글자 하나하나에 코드를 매칭
- 각 음절은 초성, 중성, 종성 순으로 정렬
- 확장 완성형과 다른 점은, 초성, 중성, 종성의 분리가 가능
- 초성은 19개, 중성은 21개, 종성은 28개로 이루어져 있음
- 유니코드 한글의 각 음소를 분리하기 참고
한글 자모, 한글 자모 확장
- 초성/종성을 구별하는 자음과 모음으로 구성
- 완성(조합 전) 문자 하나하나에 코드 매칭
- 이를 이용하여 조합형 한글을 표현할 수 있음
- 한글 자모 영역에는 옛한글에서만 사용된 초성, 중성, 종성이 있으므로, 옛한글을 표현할 수 있음
- U+1100부터 U+115E까지는 초성, U+1161부터 U+11A7까지는 중성, U+11A8부터 U+11FF까지는 종성
유니코드 정규화(Unicode equivalence)
유니코드 정규화(Unicode equivalence)란 이렇게 연속적인 코드를 사용하여 표현한 어떤 글자를 처리하는 방법을 다루는 명세이다.
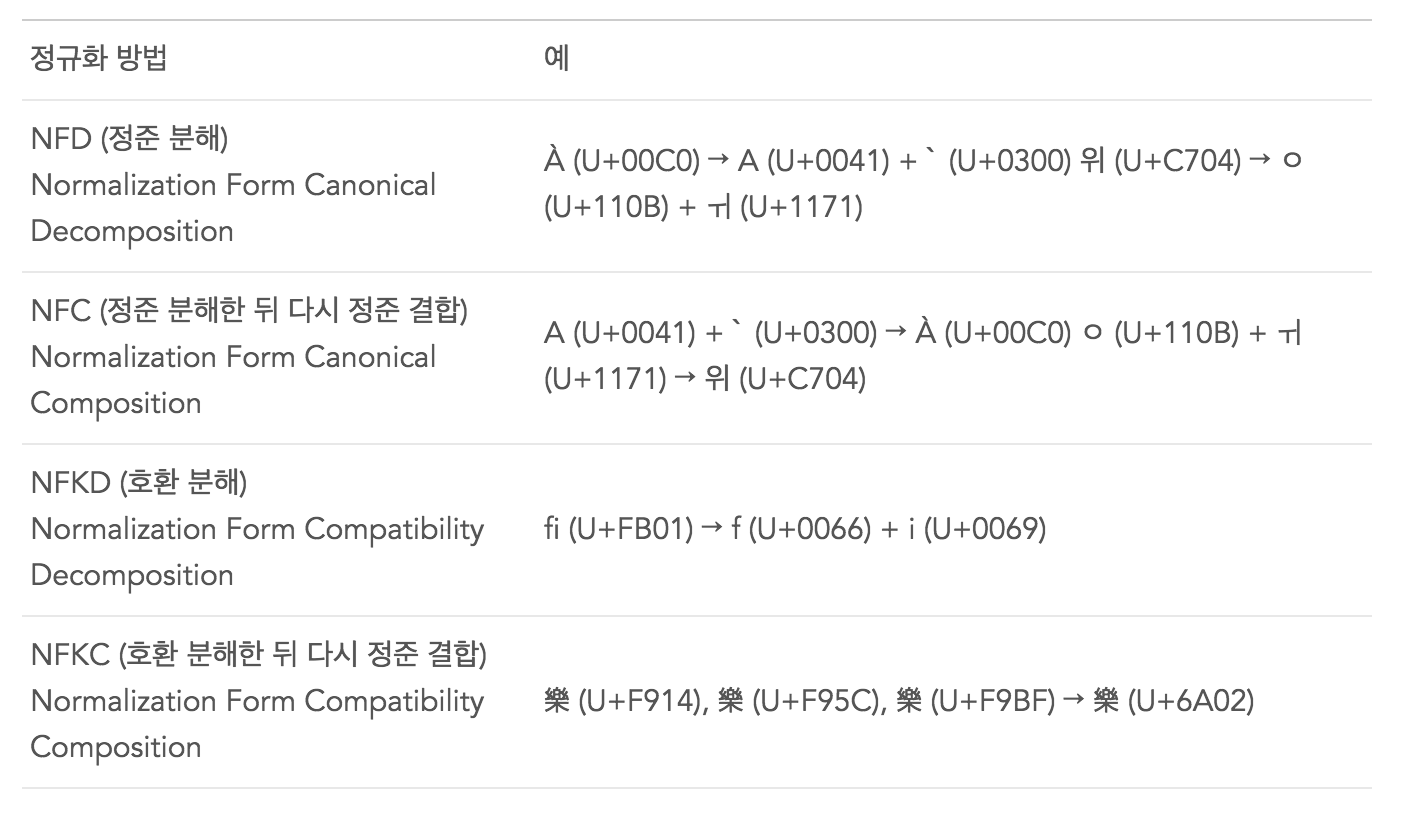
- 프로그래밍 언어의 유니코드 정규화 기능을 사용하여 문자열을 분석할 수 있다.
- ex) Swift UnicodeScalar, Swift String 문서
- 다만 사용자의 환경이 각자 다르고 엄청나게 다양하므로 수많은 인코딩과 마주칠 수 있다고 한다.
- (전반적으로 보자면 웹의 경우에)어딘가에서 한글이 깨진다면, 그 이유는 브라우저 인코딩 값과 서버 인코딩 값이 다르다는 것에 있다.
- (Tomcat에서는 파라미터 인코딩 및 키와 값을 설정하기 위해 org.apache.catalina.connector.Request.parseParameters 메서드와 org.apache.tomcat.util.http.Parameters.processParameters 메서드를 이용하여 처리하고 있다고 한다.)
- 인코딩이 올바르지 않게 설정되면 파라미터에 잘못된 값이 들어가게 된다.
- 웹에서 여러 인코딩을 지원하려면, 인코딩된 URL 문자열과 사용한 인코딩 정보를 파라미터로 전달 해야 한다.
Comments